| Home | Escopo | Processo | Design/Mockups | Configuração | Arquitetura | Gerência | BD | Qualidade | Frontend | Backend | Analytics |
|---|
Backend
Esta página centraliza informações sobre o repositório Backend do projeto Sem Barreiras.
Sumário
- Escolha de tecnologias
- Organização do repositório
- Padrões de código
- Tratamento de exceções
- Validação de parâmetros das requisições
- Documentação do Swagger
Escolha de tecnologias
Conforme mencionado na página de configuração de ambiente da Wiki, como tecnologias de Backend foram selecionadas a linguagem Java, junto ao framework Spring Boot, para o desenvolvimento da API, e o banco de dados PostgreSQL.
Esta decisão foi tomada com base em dois momentos. Em um primeiro momento, na primeira semana da Sprint 0, cada integrante citou as tecnologias com as quais tinha experiência e com qual stack tinha mais interesse em trabalhar (Frontend ou Backend) ao se apresentar. Este levantamento demonstrou que, dentre as 16 pessoas AGES 1,2 e 3 do time:
- 9 pessoas tinham experiência com Java (principalmente devido às cadeiras obrigatórias do curso de Engenharia de Software);
- 11 pessoas tinham experiência com JavaScript;
- 4 pessoas tinham experiência com JavaScript e TypeScript;
- 2 pessoas tinham experiência com Python;
- 1 pessoa tinha experiência com Ruby.
Dentre essas 5 alternativas de tecnologia para Backend, a equipe avaliou que faria mais sentido considerar as 3 primeiras (Java, JavaScript, e JavaScript + TypeScript), dado que existiria uma curva de aprendizado menor por grande parte do time já ter utilizado ou visto códigos destas tecnologias anteriormente. Além disso, tanto o Java quanto o JavaScript possuem frameworks conhecidos para o desenvolvimento de APIs Backend (Spring Boot e Node.js com Express), o que implica em muitos materiais didáticos e gratuitos para estudo na Internet.
Diante disso, em um segundo momento, após a apresentação dos stakeholders no dia 08/03/2024, foi realizada uma enquete pelos AGES 3 para que os colegas votassem na tecnologia com a qual tinham interesse em trabalhar, e esta enquete ficou ativa até o dia 11/03/2024. Abaixo, é possível ver os resultados da enquete, de modo que se percebe que as tecnologias mais votadas foram aquelas escolhidas para o projeto:
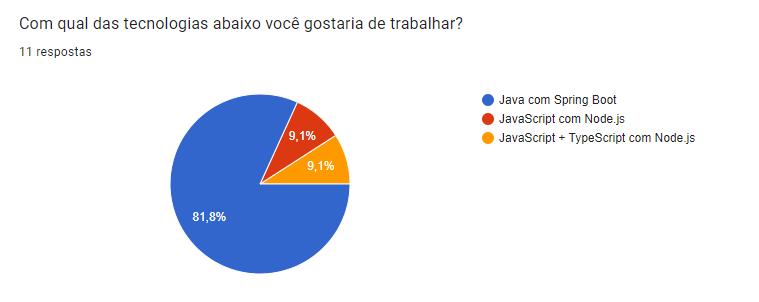
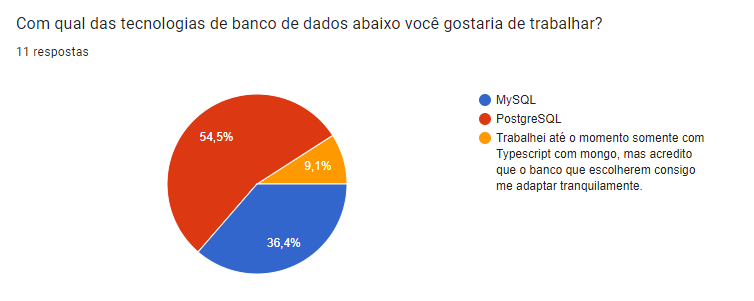
Organização do repositório
O projeto Spring Boot do repositório de Backend do projeto está organizado seguindo um padrão Controller-Service-Repository, e esse padrão está refletido na organzação de pacotes do projeto. Optou-se por esse padrão pois, ainda que este padrão possa trazer problemas como acoplamento de regras de negócio e tecnologias de ORM (sendo estes problemas que poderiam ser resolvidos com um padrão de arquitetura limpa), ele segmenta o código em camadas visando uma separação de preocupações/responsabilidades (Separation of concerns). Além disso, é um padrão fácil de entender para desenvolvedores que não possuem muita experiência com Spring Boot ou com o desenvolvimento de APIs em geral.
Diante disso, os pacotes do projeto estão divididos da forma abaixo:
-
📁 config: Configurações personalizadas da aplicação (ex.: configuração da conexão com o banco de dados, declaração de Beans). -
📁 controller: Expõe pontos de entrada para comunicação com o mundo exterior. Neste projeto, gerencia a API REST da aplicação, incluindo responsabilidades como autenticação e autorização, e delega o processamento de lógica de negócio para a camada de _services*. -
📁 dto: Classes utilizadas para transferir dados entre camadas de uma aplicação (não são entidades, são apenas classes que modelam essas informações a serem trafegadas na aplicação).-
📁 request: DTOs para dados de entrada das requisições. -
📁 response: DTOs para dados de resposta das requisições.
-
-
📁 exception: Exceções personalizadas da aplicação. -
📁 model: Entidades do negócio. -
📁 repository: Encapsula a lógica de acesso ao banco de dados para buscar e persistir dados.-
📁 impl: Classes que implementam as interfaces em _repository*.
-
-
📁 service: Implementação da lógica de negócio (interfaces). Se necessário buscar ou salvar dados, delega isso para a camada de _repository*.-
📁 impl: Classes que implementam as interfaces em _service*.
-
-
📁 util: Classes e métodos utilitários (ex.: formatação de datas)
Padrões de código
Nomenclatura de classes
Classes do projeto devem ser nomeadas em inglês e seguir o padrão PascalCase, ou seja, devem iniciar com letra maiúscula e cada palavra ou abreviatura no meio da frase também deve iniciar com letra maiúscula. Por exemplo:
- UserController
✔ - User_Controller
❌ - Usercontroller
❌ - userController
❌
Além disso, com exceção do pacote model, os nomes das classes devem refletir o pacote onde elas estão localizadas, conforme o exemplo abaixo:
-
📁 config: ExemploConfig -
📁 controller: ExemploController -
📁 dt.request: ExemploRequest -
📁 dt.response: ExemploResponse -
📁 exception: ExemploException -
📁 repository: ExemploRepository -
📁 service: ExemploService -
📁 util: ExemploUtil
Nomenclatura de variáveis
Variáveis devem ser nomeadas em inglês e seguir o padrão camelCase, ou seja, devem iniciar com letra minúscula e cada palavra ou abreviatura no meio da frase deve iniciar com letra maiúscula. Por exemplo:
- isAdmin
✔ - isadmin
❌ - is_Admin
❌ - IsAdmin
❌
A exceção são as variáveis constantes (que devem ser estáticas e finais) e enums, que devem seguir o padrão SCREAMING_SNAKE_CASE, onde as palavras no meio da frase são separadas por underscores (_) e as letras devem ser todas maiúsculas. Por exemplo: API_BASE_URL
Além disso, para criar um código limpo e fácil de entender e realizar a manutenção depois, sempre nomeie as variáveis de forma que fique claro o seu propósito/o tipo de informação que ela possui. Para isso, seguem algumas dicas:
- Evitar abreviações.
- Para variáveis booleanas, não nomear apenas com substantivos, para deixar claro que é um booleano. Por exemplo, ao invés de "publish", usem "isPublished".
- Criar variáveis fáceis de pronunciar.
- Evitar dar nomes muito parecidos para duas variáveis.
- Não usar números mágicos. Se existir algum número que precisa ser utilizado no código, criar uma variável para este número para deixar claro o que ele significa.
Nomenclatura de métodos
Variáveis devem ser nomeadas em inglês e seguir o padrão camelCase, ou seja, devem iniciar com letra minúscula e cada palavra ou abreviatura no meio da frase deve iniciar com letra maiúscula. Por exemplo:
- findUserByName
✔ - finduserbyname
❌ - find_User_By_Name
❌ - FindUserByName
❌
Além disso, para facilitar a leitura do código, em uma classe os métodos sempre devem estar organizados na ordem abaixo:
- Métodos
public - Métodos
protected - Métodos
private
Padrões das APIs REST
A API desenvolvida para este projeto deverá seguir o estilo de arquitetura REST, muito utilizado para o desenvolvimento de APIs web, e para isso algumas restrições e boas práticas devem ser seguidos. Neste estilo, as informações gerenciadas pela aplicação e que possuem uma identificação única são chamadas de recursos (pode-se dizer que são mapeamentos conceituais/abstratos às entidades da aplicação), e as URIs da aplicação (Uniform Resource Identifiers) devem referenciar estes recursos de forma clara e padronizada.
Abaixo segue um exemplo de uma API fictícia para ilustrar o padrão que deve ser utilizado pela aplicação:
- GET /v1/books - buscar lista/coleção de livros
- GET /v1/books/1 - buscar um livro específico a partir de um identificador único
- POST /v1/books - criar/registrar um novo livro
- PATCH /v1/books/1 - editar um livro específico a partir de um identificador único (atualizações parciais)
- PUT /v1/books/1 - editar um livro específico a partir de um identificador único (substituindo a representação do recurso pelos novos dados informados)
- DELETE /v1/books/1 - deletar um livro específico a partir de um identificador único
Os recursos devem ser referenciados como substantivos no plural, e também deve se adicionar o versionamento da API no começo do path, conforme exemplos acima. Além disso, caso exista algum recurso que precise ser representado com mais de uma palavra, estas devem ser separadas por hífens, por exemplo: /v1/loan-contracts
Para mais informações, sugere-se a leitura deste link, que traz algumas boas práticas de forma didática.
Checkstyle
Para estabelecer padrões e regras de codificação no projeto, e verificar de forma fácil se o código escrito está aderente a estas regras ou não, estabeleceu-se no projeto o uso da ferramenta Checkstyle, que realiza uma análise de código estático e aponta os pontos do código implementado onde ocorreram violações dos padrões. Para este projeto, foi habilitada a verificação das convenções de "Sun's Java Style", que podem ser vistas nesta documentação.
As instruções de como executar a análise do Checkstyle no projeto podem ser vistas no README do repositório de Backend.
Tratamento de exceções
No projeto, dentro do pacote config, existe a classe GlobalExceptionHandler, que foi criada para que as exceções lançadas pela a aplicação durante a execução sejam tratadas e retornadas com um corpo de resposta e status HTTP de resposta apropriados.
Em casos de erro, o corpo da resposta deve sempre seguir um formato padronizado, conforme exemplo abaixo. Este formato é aquele modelado pela classe ErrorResponse.
{
"error": "Mensagem da excecao"
}Para garantir que esse padrão seja seguido para as diferentes exceções que possam ocorrer, foi criado um método genérico para tratamento de exceção nesta classe GlobalExceptionHandler onde, ao ser lançada uma exceção do tipo HttpException, retorna-se uma resposta com a mensagem e o status HTTP que são atributos desta classe.
Ou seja, novas exceções criadas dentro do pacote exception devem ser subclasses da classe pai HttpException, e devem informar no construtor o status HTTP a ser retornado e a mensagem de erro. Assim, será feito o tratamento descrito acima sem precisar de nenhum código adicional.
Para mais informações, leia esta documentação do Spring.
Validação de parâmetros das requisições
Ao receber uma nova requisição, é importante verificar se os parâmetros necessários vieram preenchidos de forma completa e com valores que façam sentido. Uma forma na qual se pode fazer isso é utilizando a API de validação de Beans do Java.
A API disponibiliza várias anotações que podem ser utilizadas para validar diferentes cenários, a exemplo de:
- @NotNull: verifica se a variável/atributo é nulo.
- @NotBlank: verifica se a variável/atributo String é nulo ou é uma String vazia.
- @Min: verifica se a variável/atributo tem valor igual ou maior que o valor mínimo informado.
- @Max: verifica se a variável/atributo tem valor igual ou menor que o valor máximo informado.
Supondo um cenário onde existe um endpoint de uma aplicação de biblioteca, para registro de novos livros, onde se recebe um corpo de requisição JSON, para realizar a validação precisariam ser feitos os ajustes abaixo:
- Na classe DTO que modela os dados do corpo da requisição, adicionar as anotações nos atributos que se deseja validar.
public class BookRequest { @NotBlank(message = "Titulo precisa ser informado.") private String title; @NotBlank(message = "Autor precisa ser informado.") private String author; @Min(value = 1, message = "Ano de lancamento precisa ser valido.") private Integer releaseYear; } - Adicionar a anotação @Valid no método do controller onde se recebe o corpo da requisição.
java @PostMapping public BookResponse createBook(@Valid @RequestBody BookRequest bookRequest) { ... }Para mais informações, leia esta página.
Documentação do Swagger
A ferramenta Swagger (OpenAPI) já foi configurada na aplicação, para documentação da API e para permitir testar requisições HTTP via interface gráfica. Diante disso, novos controllers REST que forem criados já vão ser exibidos na url do Swagger sem precisar de nenhuma configuração adicional.
No entanto, para garantir que a API esteja bem documentada, sugere-se utilizar as anotações da API do Swagger para descrever melhor quais são os propósitos de cada endpoint e quais são os significados de cada parâmetro de requisição e código de resposta. Seguem alguns exemplos de anotação abaixo:
- @Operation: usada para descrever uma operação no Swagger (adicionar resumo, tags, etc)
- @Parameter: usada para descrever um parâmetro de uma requisição HTTP (propósito do parâmetro, exemplo de valor, etc)
Para mais informações, leia esta página.