Eduarda
Eduarda| Home | Sprints | Requisitos | Arquitetura | Configuração | Mockups | Banco de Dados | Instalação | Gerência de Projeto | Git | Boas Práticas | Merge Request Template |
|---|
Página do Banco de Dados
Os bancos de dados relacionais utilizam SQL (Structured Querying Language), sendo uma escolha adequada para aplicativos que envolvam o gerenciamento de várias transações. A estrutura de um banco de dados relacional permite vincular informações de diferentes tabelas por meio do uso de chaves estrangeiras. Cada tabela em um banco de dados relacional contém um ou mais dados em colunas, e cada linha, também chamada de registro, contém uma instância exclusiva de dados ou chave para os dados definidos pelas colunas. Cada tabela normalmente possui uma coluna de chave primária, um registro único dentro da tabela para identificar os registros.
Ao analisarmos o nosso projeto, percebemos que a melhor escolha seria um modelo relacional. Pois ele nos garante o ACID (Atomicidade, Consistência, Isolamento, Durabilidade). O ACID reduz possíveis irregularidades e protege a integridade do banco de dados. Ele consegue fazer isso porquê define exatamente como as transações interagem com o banco de dados. Além disso, um banco de dados relacional nos fornece a estrutura necessária para trabalhar com um grande volume de dados e consultas. O banco de dados escolhido foi o PostgresSQL e além dele fazer a comunicação com o Backend ele também se comunica com um micro serviço que é responsável por fazer a carga de dados para o banco.
Link dos arquivos para fazer download
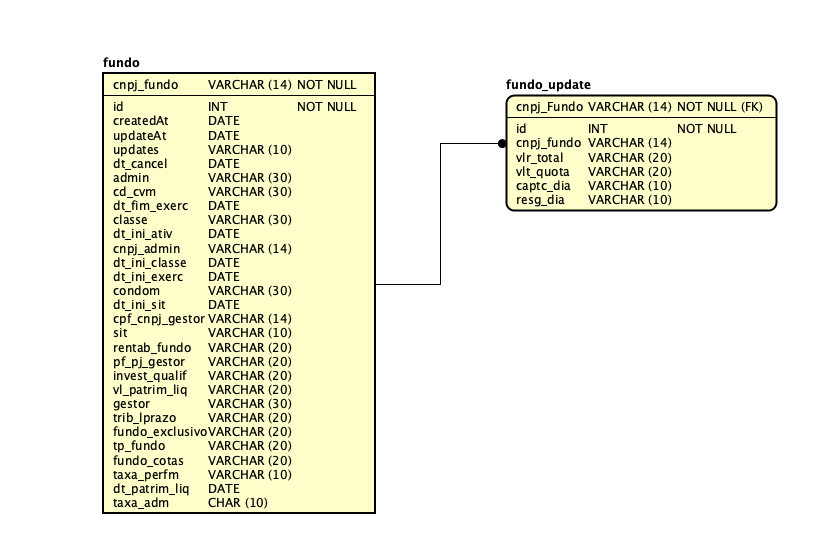
Modelo Conceitual do Banco de Dados
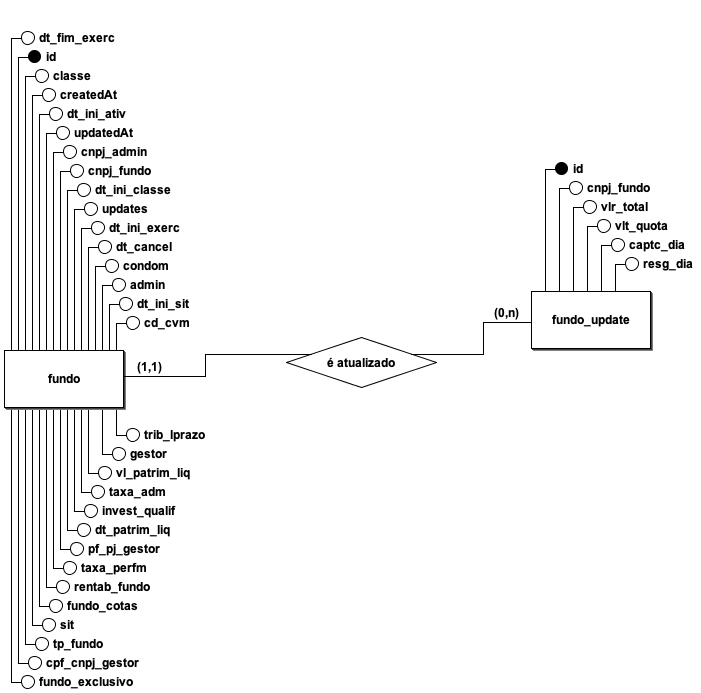
Modelo Lógico do Banco de Dados