|[Home](home)|[Escopo](escopo)|[Arquitetura](arquitetura)|[Configuração](configuracao)|[Mockups](mockups)|[**BD**](banco_dados)|[Instalação](instalacao)|[Gerência](gp)|[Qualidade](qualidade)|[Processo](processo)|
|---|---|---|---|---|---|---|---|---|---|
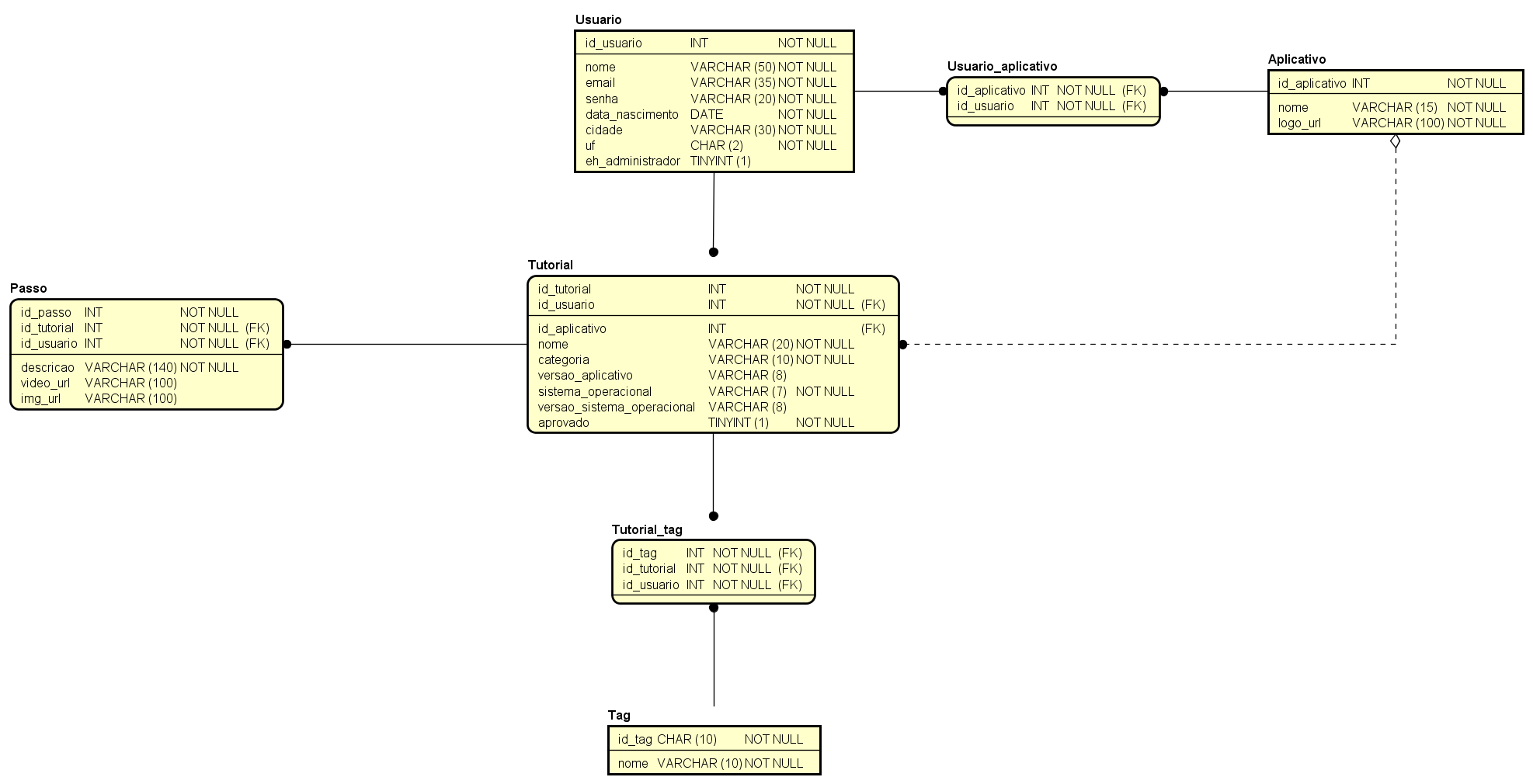
# Banco de Dados
### Cenário
Durante a conversa com a equipe, foram levantados alguns pontos que nos levaram a decidir qual tipo de implementação iríamos utilizar.
Quando utilizar banco relacional(Tables): Utiliza-se um modelo relacional quando há muitas relações diretas entre as entidades, e, acima de tudo, se esses dados dificilmente se repetem. Por exemplo: Um piloto de fórmula 1 que irá correr em um determinado evento, num determinado local, num determinado horário. Rapidamente observamos muitas relações entre esses três fatores e que esses dados dificilmente irão mudar. Em outras palavras, precisamos garantir a integridade desses dados seguindo boas práticas como o ACID(Atomicidade, Consistência, Isolamento e Durabilidade).
Quando utilizar banco não-relacional (Collections): Utiliza-se um modelo não-relacional quando não há muitas relações entre entidades e os dados se repetem com frequência. Por exemplo: Um carrinho de compra em um e-commerce. Um usuário pode adicionar itens no carrinho ou removê-los, ou também não finalizar a compra no mesmo dia. Quando precisamos lidar com um grande volume de dados e que terá muito acesso, então noSQL é a escolha certa.
### Conclusão do estudo
Ao analisarmos o nosso case, percebemos que a melhor escolha seria um modelo relacional. Pois tutoriais não são dados que mudam com frequência e precisávamos garantir a integridade de modo que os dados não ficassem redundantes.
### Nossa escolha
Ok, decidimos que iremos utilizar SQL. Mas qual devemos utilizar? Bem, essa pergunta tem muitas variantes. Precisamos estudar o conhecimento técnico da equipe e também qual banco seria mais fácil de configurar de modo que todos conseguissem utilizar sem nenhum impedimento. Foi então que decidimos utilizar o MySQL hospedado no Amazon Web Service(AWS). Desse modo nos livramos da preocupação de rodar o banco localmente na máquina de todos, o que poderia provocar vários erros.
### Mapeamento conceitual
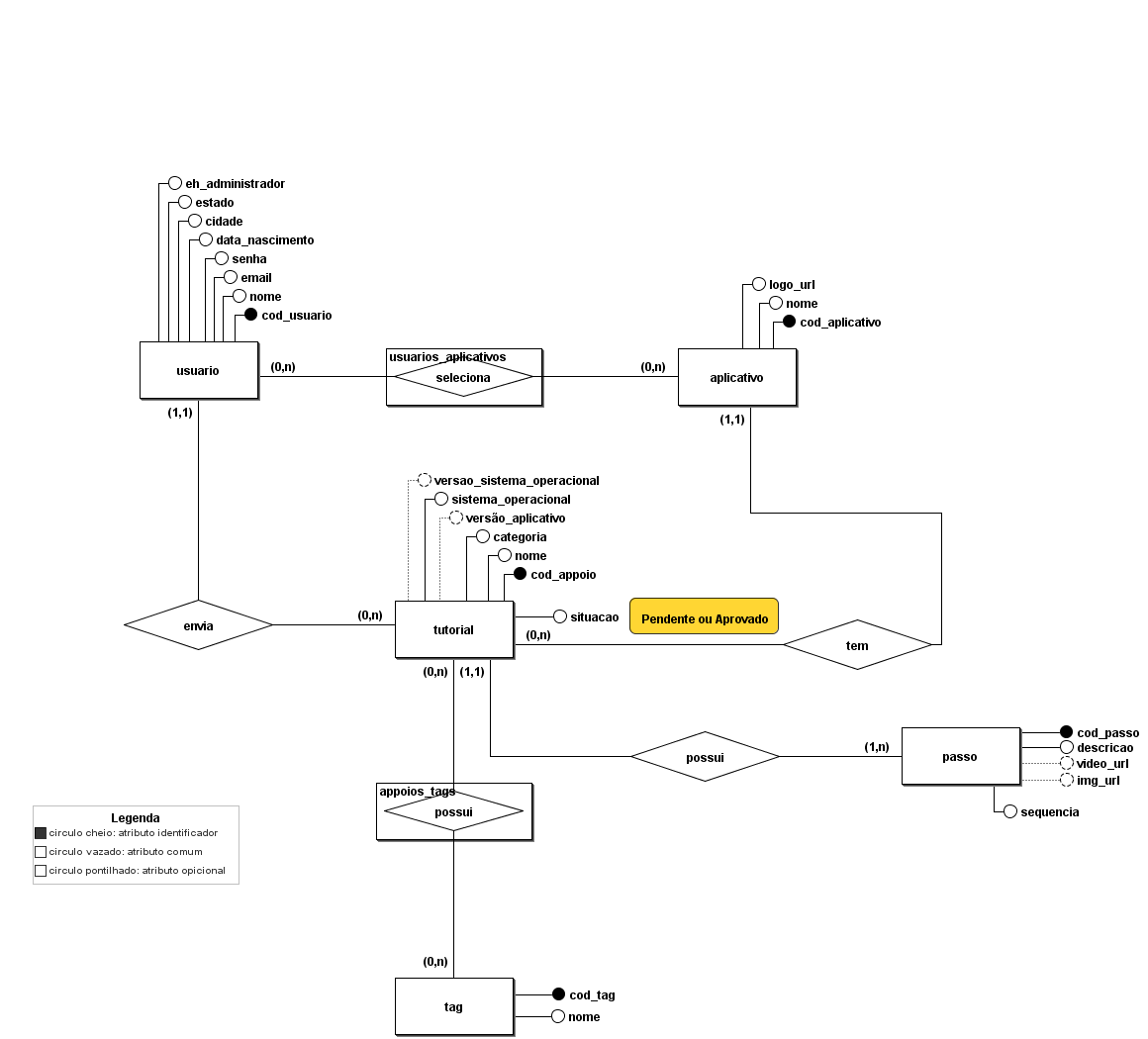
### Mapeamento lógico